
Reinforcement Learning for Ad Campaign Optimization
RL dynamically adjusts bids, budgets and creatives in real time to boost CTR, ROAS and conversions across major ad platforms.
Reinforcement learning (RL) is transforming digital advertising. Unlike outdated, static rules, RL uses AI to optimize ad campaigns in real-time, improving metrics like click-through rate (CTR), return on ad spend (ROAS), and conversions. By learning from live feedback, RL systems outperform manual methods and AI tools for optimizing paid ads.
Key takeaways:
RL systems adjust bids, budgets, and ad placements dynamically, responding to changing conditions.
Case studies show impressive results: a 23% increase in ROAS, a 67.8% rise in purchases, and reduced costs per click and impressions.
Algorithms like Deep Q-Learning, PPO, and Contextual Bandits power these systems, enabling smarter decisions in milliseconds.
RL excels in multi-platform campaigns, efficiently allocating budgets across Meta, Google, TikTok, and more.
While challenges like delayed data and reward shaping persist, RL is quickly becoming a must-have for advertisers aiming to stay competitive in the $513 billion digital ad market.
Applied Reinforcement Learning for Online Ads/Recommender - Kevin Noel
How Reinforcement Learning Works in Ad Campaigns
Reinforcement learning (RL) in ad campaigns functions through a dynamic loop where an AI agent observes campaign performance, makes adjustments, and receives feedback. The agent acts as the decision-maker, while the ad platform - like Meta Ads Manager - serves as the environment. By monitoring key metrics such as daily impressions, remaining budget, and progress toward campaign goals, the agent continuously refines its approach. Let’s break down how these components work and see how they’re applied in practice.
Agents and Environments in Ad Campaigns
In this system, the agent interacts with the advertising ecosystem much like a human media buyer would - but at the speed of a machine. The agent evaluates the current state of a campaign by tracking metrics like total impressions delivered, remaining time in the day, and available budget. Based on this data, it takes actions such as adjusting automated bid rules, enabling or disabling placements (e.g., prioritizing Facebook Feed over Stories), or setting frequency caps to control ad exposure.
For example, between July and November 2024, the German agency Stellwerk3 used the pi_optimal platform to manage over 60 campaigns. The RL agent made hourly adjustments to bidding and frequency settings, leading to a 24% reduction in Cost Per Click (CPC) and a 31% drop in Cost Per Mille (CPM).
Rewards and Feedback in Optimization
After the agent executes an action, it evaluates the outcome through immediate feedback. This continuous loop of action, feedback, and adjustment allows RL systems to outperform static, rule-based approaches. Each action generates a numerical reward that reflects its impact on campaign goals - whether it’s boosting click-through rates, improving return on ad spend (ROAS), or narrowing the gap between target and actual impressions.
Take the example of Dyut.eu, a premium skincare brand. From September 25 to October 25, 2024, they used AdAmigo.ai in full autopilot mode. During this period, the AI executed 163 actions, including 41 budget adjustments, 26 audience optimizations, and 63 new ad creatives. The results? ROAS increased by 23%, purchases rose by 67.8%, and the cost per add-to-cart dropped by 13.2%. The reward system guided the AI to reallocate budget toward strategies that performed well while avoiding those that didn’t.
Exploration vs. Exploitation Tradeoff
A key challenge for RL agents is balancing exploration - trying out new audiences, placements, or bid levels - with exploitation, where the focus is on scaling strategies that are already working. Exploration can be costly since it involves spending budget on untested methods. As BK Park, an industry expert, explains:
"Reinforcement learning systems don't begin life as experts. Early on, they explore."
To reduce unnecessary spending, advanced RL systems often use historical auction data to "warm-start" before launching live campaigns. Over time, as the agent gathers more data, it shifts from broad testing to honing in on the most effective strategies. This ability to adapt and refine sets reinforcement learning apart from static, rule-based methods.
Common Reinforcement Learning Algorithms for Ad Optimization

Reinforcement Learning Algorithms for Ad Campaign Optimization Comparison
Reinforcement learning (RL) algorithms have become a cornerstone in modern ad platforms, enabling precise decision-making to optimize campaign outcomes. These algorithms address challenges like determining bid amounts in milliseconds or selecting the most engaging ad creative for a specific audience. By leveraging RL, platforms often surpass the capabilities of traditional rule-based systems.
Deep Q-Learning Networks (DQN)
Deep Q-Learning transforms real-time bidding into a decision-making process rather than just a predictive one. Instead of merely estimating an impression's value, DQN evaluates scenarios like:
"Should I skip this decent impression so I can afford better ones later today? That's not a prediction problem. That's a decision problem."
The algorithm calculates the "Q-value", which represents the expected return of placing a specific bid based on the campaign's current state. This includes factors like the remaining budget, time of day, and past performance. Given that real-time bidding must conclude in under 100 milliseconds, DQN performs these calculations at lightning speed. To ensure spending stays within limits, practitioners apply hard-bounded constraints during the bidding process.
Actor-Critic Methods
Actor-Critic algorithms, such as Proximal Policy Optimization (PPO), are particularly effective for balancing short-term results with long-term campaign goals. These models consist of two components: the "Actor", which takes actions like adjusting budgets or generating ad text, and the "Critic", which assesses the impact of those actions using metrics like click-through rate (CTR) or customer lifetime value.
In early 2024, Meta introduced AdLlama, a 7-billion-parameter model trained with PPO and Reinforcement Learning with Performance Feedback (RLPF). Spearheaded by Daniel R. Jiang and Alex Nikulkov, the project involved 34,849 advertisers and 640,000 ad variations. The RL-driven model achieved a 6.7% improvement in advertiser-level CTR compared to a traditional supervised model. Additionally, advertisers created 18.5% more ad variations, suggesting higher satisfaction with AI-generated content.
PPO’s controlled updates help maintain stability, avoiding erratic bidding patterns and managing delayed conversion signals effectively. Meta’s AdLlama experiment highlights how these features can drive measurable performance gains.
Contextual Bandits for Ad Selection
Contextual Bandits simplify reinforcement learning by treating each ad impression as a standalone decision. Using function approximation, they match user context - like location, device, or browsing behavior - with the ad creative most likely to perform well for that audience segment.
Unlike static A/B testing, which may overlook subtle performance differences (e.g., a 0.2% CTR variance), Contextual Bandits continuously explore new options while prioritizing the best-performing ones in real time. This makes them ideal for creative selection and personalization, especially when immediate engagement is the goal.
Here’s a quick comparison of these algorithms and their strengths:
Algorithm Type | Primary Application | Key Strength | Best Use Case |
|---|---|---|---|
Deep Q-Learning (DQN) | Real-Time Bidding (RTB) | Calculates optimal bids while respecting budget limits | Deciding whether to bid on impressions based on the daily budget |
Actor-Critic (PPO) | Long-term ROI & Ad Text Generation | Ensures stable updates and handles delayed conversions | Optimizing for lifetime value or generating high-CTR ad copy |
Contextual Bandits | Creative Selection & Targeting | Balances exploration with scaling of high-performing ads | Personalizing ad creatives for diverse user segments |
Case Studies and Performance Metrics
Documented Performance Gains
Reinforcement learning (RL) has shown it can deliver measurable improvements over traditional optimization methods. For instance, Meta's AdLlama model, which uses Reinforcement Learning with Performance Feedback (RLPF), increased advertiser-level click-through rates (CTR) by 6.7% compared to standard models. Advertisers using this system also created 18.5% more ad variations.
The German advertising agency Stellwerk3 achieved notable results by incorporating model-based reinforcement learning through the pi_optimal platform. This approach automated over 60 campaigns, reducing cost-per-click (CPC) by 24% and cost-per-thousand impressions (CPM) by 31%, with a 91% success rate in automation. Broader industry data supports these findings, showing that real-time AI optimization delivers an average conversion lift of 37%, compared to just 8% from manual or batch optimization methods. Additionally, it provides approximately 22% cost savings, far surpassing the 4% achieved through manual management.
These performance metrics highlight the potential of RL to transform advertising strategies across various platforms and campaigns.
Applications in Cross-Channel Budget Allocation
Reinforcement learning's ability to adapt extends naturally to multi-platform budget management. By treating the advertising ecosystem as a dynamic environment, RL agents learn to allocate funds based on real-time metrics like return on ad spend (ROAS) and cost per acquisition (CPA). Unlike static systems that rely on historical data, RL agents continually adjust their strategies as performance data shifts.
One of RL's standout features is its ability to balance the exploration–exploitation tradeoff. Instead of funneling all resources into historically successful channels, RL allocates smaller test budgets to explore new opportunities while scaling investments in proven performers. This dynamic method enables platforms using RL-driven predictive models to optimize budgets across multiple channels - such as Meta, Google, and TikTok - simultaneously. These systems adjust in real-time, responding to fluctuations in conversion rates and costs.
AdAmigo.ai as a Practical Example
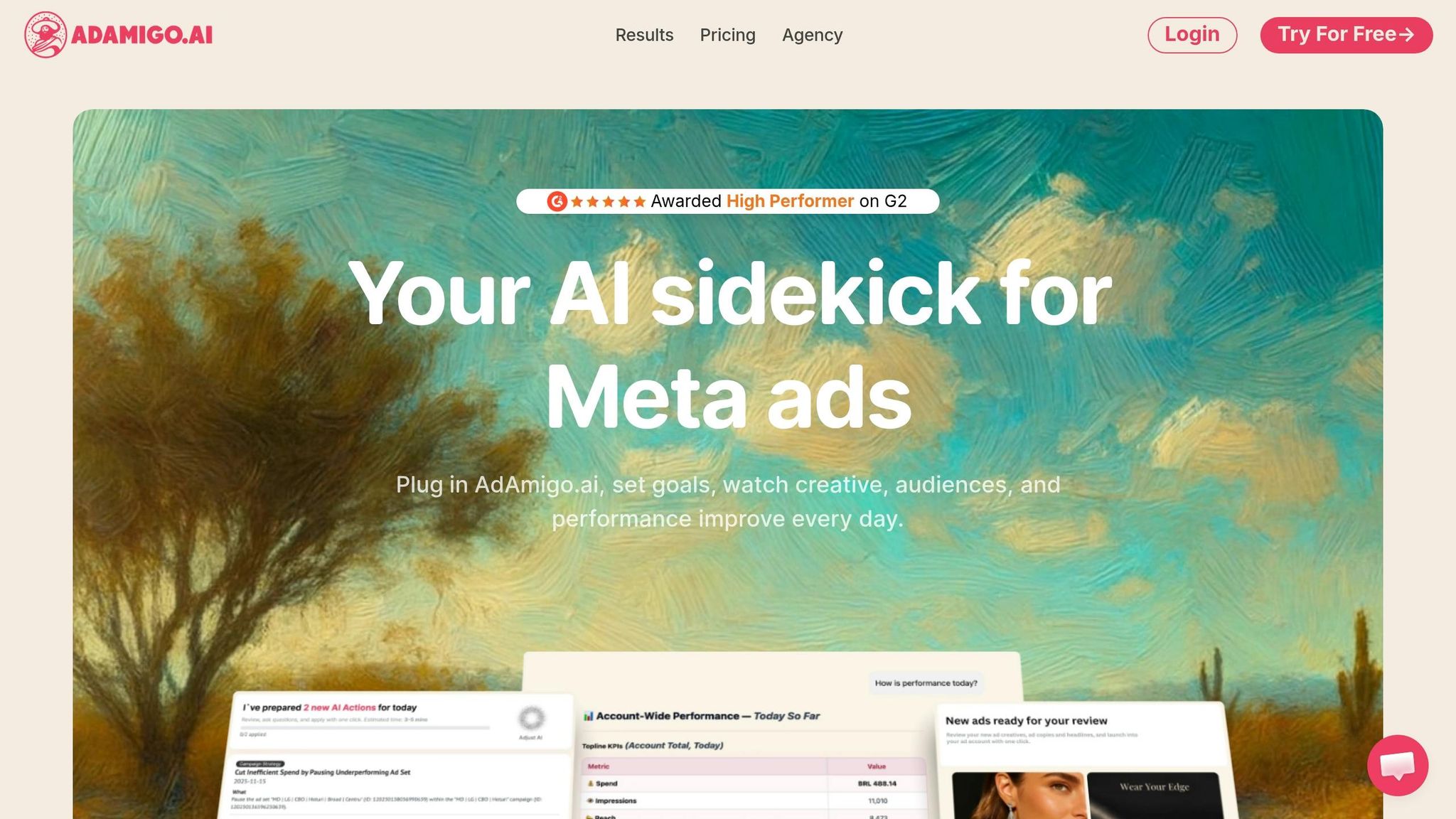
AdAmigo.ai provides a concrete example of how RL principles can be applied to campaign management. The platform's interconnected features - like its AI Ads Agent for creative generation and AI Actions for daily optimizations - work together to manage creatives, targeting, budgets, and bids as a unified system rather than treating each element separately.
From September 25, 2024, to October 25, 2024, the premium skincare brand Dyut.eu fully adopted AdAmigo.ai's autopilot mode for its Meta ad account. Under the guidance of co-founder Shubham, the brand transitioned from manual management to AI-driven optimization. Over 30 days, the AI system executed 163 actions, which included building 11 audiences and creating 63 ads. The results were impressive: ROAS improved by 23%, purchases increased by 67.8%, and the cost per add-to-cart dropped by 13.2%. Additionally, the team saved 18.3 hours of manual work.
"This is the future of media buying. It's incredibly refreshing to be able to launch a campaign through AI prompts. The AI recommendations go beyond simply suggesting actions - they provide valuable insights and justifications."
Shubham, Co-Founder, Dyut.eu
The campaign's purchases grew nearly twice as fast as its ad spend (67.8% versus 36.6%), showing that the RL-driven system didn’t just spend more - it found smarter ways to scale campaigns. This example illustrates the power of RL to combine multiple optimization strategies into one cohesive approach, achieving both performance gains and efficient budget management.
Challenges and Future Directions
While reinforcement learning (RL) methods have demonstrated measurable progress, they still face hurdles and present evolving opportunities.
Challenges in Reward Shaping and Data Delays
Defining the right reward signal is tricky. Metrics like click-through rate (CTR) often lead agents to focus on clicks rather than meaningful outcomes like return on ad spend (ROAS). To address this, projects such as Meta's AdLlama have explored using more nuanced reward techniques, including pairwise preference data and penalties for undesired behaviors like overly long engagement times.
Another significant challenge is delayed performance data, which can lag by several hours. This delay makes it hard for RL models to adapt to sudden changes like creative fatigue or auction dynamics. For example, ad engagement can decline by 40%–60% within weeks, yet delayed feedback may prevent models from pausing underperforming creatives before budgets are wasted. To counter this, RL agents often rely on recent historical data to recalibrate their strategies. Tools like server-side tracking via Conversions API (CAPI) offer some relief by providing first-party data signals, reducing dependence on delayed reporting from platforms.
When campaigns span multiple platforms, these challenges become even more complex.
Scaling RL for Multi-Channel Campaigns
Expanding RL to manage campaigns across multiple platforms introduces additional layers of complexity. Each platform - whether Meta, Google, or TikTok - comes with its own auction dynamics, audience behaviors, and reporting delays. The real challenge lies in building a reward function that balances performance across all these environments. Without careful calibration, an agent might allocate too much budget to a high-performing channel while ignoring opportunities in others.
One approach to this problem involves hierarchical reward structures that emphasize key outcomes like ROAS or cost per acquisition (CPA) over superficial metrics. Additionally, modern RL frameworks are adopting multi-step planning to predict future outcomes. This allows agents to make proactive adjustments to budgets and bids rather than simply reacting to changes. For instance, the RL agent can oversee high-level budget distribution and creative inputs, while platform-specific algorithms - such as Meta's Advantage+ - handle the finer details of bid optimization.
Tackling these challenges could lead to even greater optimization, building on the advancements already seen in RL-driven campaigns.
Future Potential of RL in Ad Tech
The future of RL in advertising is heading toward full autonomy and seamless cross-channel management. By 2027–2028, AI systems are expected to handle entire campaigns across multiple platforms with minimal human input. Some advanced systems are already incorporating tools like the Model Context Protocol (MCP), enabling marketers to manage RL-driven campaigns through simple natural language commands. Instead of manually tweaking bids or budgets, advertisers could simply instruct the system - for example, "Increase spend by 30% while maintaining a 3× ROAS" - and let the AI handle the execution.
Emerging capabilities also include real-time creative swaps triggered by factors like local weather, sentiment trends, or live events. Predictive audience modeling is evolving, too, moving beyond static lookalike models to dynamically uncover high-value customer traits as new campaign data comes in. As of 2024, 69.1% of marketers already integrate AI into their daily workflows - up from 61% the previous year. The AI marketing industry has grown to $20.4 billion, with a projected annual growth rate of 25%. This shift from rule-based automation to adaptive learning agents is accelerating. Platforms like AdAmigo.ai already demonstrate this potential, automating hundreds of optimizations and saving marketing teams over 18 hours of manual work each month.
Conclusion
Real-time AI optimization has proven to deliver impressive results, including a 37% conversion lift, compared to just 8% for manual vs AI-powered management methods. On top of that, RL-driven platforms have shown the ability to reduce CPC by 24% and CPM by 31%, while saving marketers over 18 hours of manual work each month.
The transition from traditional rule-based automation to adaptive learning agents is picking up speed. Case studies highlight how RL automation, such as that provided by platforms like AdAmigo.ai, has led to measurable improvements: a 23% increase in ROAS, a 67.8% rise in purchases, and 13.2% lower costs per add-to-cart. These results emphasize the efficiency and effectiveness of using AI to manage campaigns.
Platforms like AdAmigo.ai showcase how RL systems bring together creative testing, audience targeting, and budget optimization. Marketers can link their Meta ad accounts, set their KPIs, and let the AI take over - whether through approval-based workflows or full automation. The platform's learning agent continuously adjusts strategies based on live performance data, ensuring campaigns evolve and improve rather than hit a performance ceiling.
These measurable outcomes highlight the growing advantage of RL over older methods. With the AI marketing industry expected to reach $20.4 billion in 2024 and grow at an annual rate of 25%, adopting RL systems is no longer optional. The gap between AI-powered campaigns and manual management is expanding, and brands that act quickly will gain the scalability, efficiency, and performance edge needed to lead in the evolving digital advertising landscape.
FAQs
What data do I need to start using RL for ad optimization?
To apply reinforcement learning (RL) in ad optimization, you'll need a well-structured dataset containing historical campaign data. This data should include essential metrics and actions, such as:
Campaign settings: Details like audience targeting, budgets, and creatives.
Performance outcomes: Metrics like click-through rates (CTR), cost per click (CPC), impressions, and conversions.
Action history: Records of decisions made by campaign managers or automated systems, along with the results of those actions.
This comprehensive dataset allows the RL model to analyze past decisions, understand their impact, and improve future ad performance.
How do RL systems handle delayed conversions and reporting lag?
Reinforcement learning (RL) systems tackle the challenge of delayed conversions and reporting lags by factoring in the time gap between when an ad interaction happens and when the outcome is realized. They adjust their reward signals to include delayed feedback, allowing the RL agent to learn from conversions that occur after some time has passed.
In some cases, these systems combine RL with multi-armed bandit algorithms. This approach helps strike a balance between exploring new strategies and exploiting known ones, effectively adapting to delays while optimizing decisions to improve long-term campaign results.
How can RL allocate budget across Meta, Google, and TikTok without overspending?
Reinforcement learning (RL) takes a dynamic approach to budget allocation across platforms like Meta, Google, and TikTok. By analyzing campaign performance in real time, RL models adjust spending to maximize ROI. These models continuously learn and reallocate budgets based on data, ensuring resources are used effectively while staying within set constraints. They also respond to shifts in the market, helping maintain efficient distribution across channels, avoid overspending, and keep campaigns on track.